[Sep. 2022] Our paper has been accepted to NeurIPS 2022.
Abstract
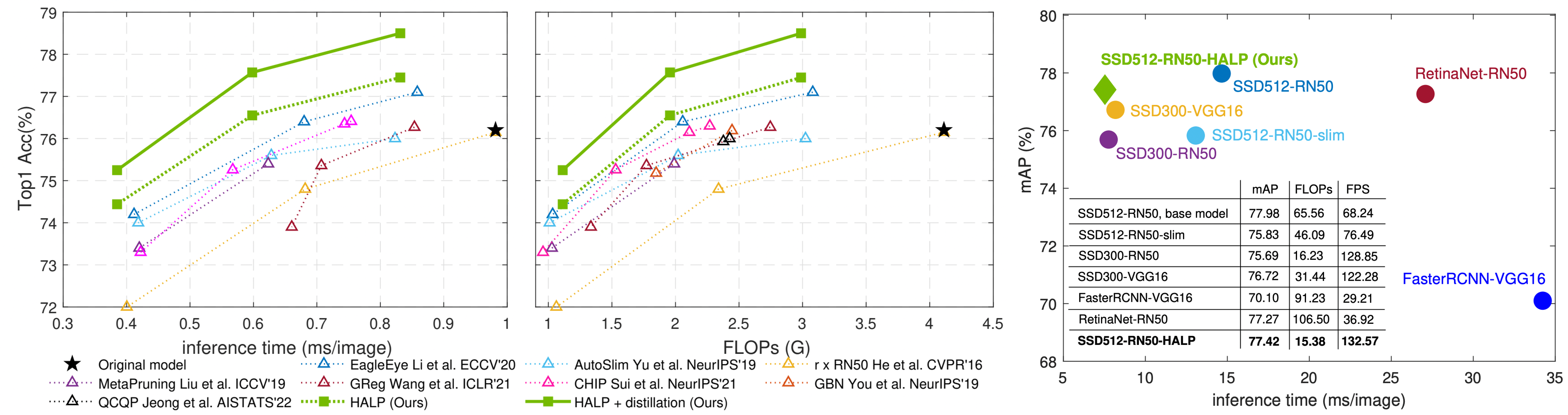
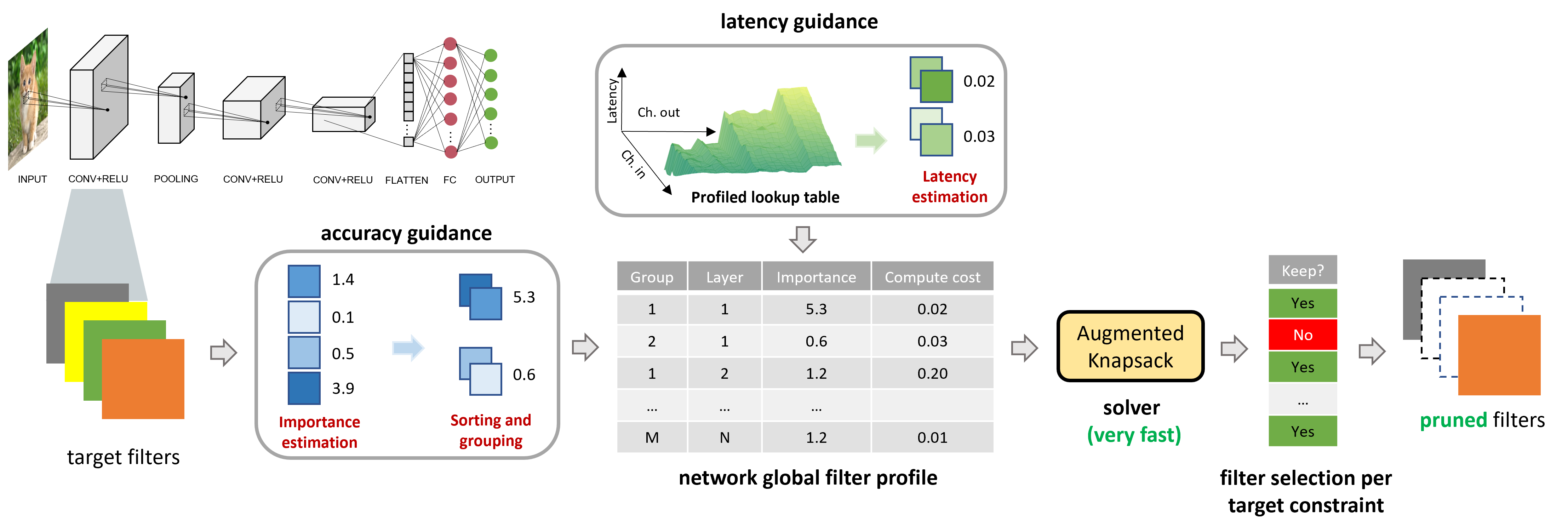
We propose Hardware-Aware Latency Pruning (HALP) that formulates structural pruning as a global resource allocation optimization problem, aiming at maximizing the accuracy while constraining latency under a predefined budget on targeting device. For filter importance ranking, HALP leverages latency lookup table to track latency reduction potential and global saliency score to gauge accuracy drop. Both metrics can be evaluated very efficiently during pruning, allowing us to reformulate global structural pruning under a reward maximization problem given target constraint. This makes the problem solvable via our augmented knapsack solver, enabling HALP to surpass prior work in pruning efficacy and accuracy-efficiency trade-off. It consistently outperforms prior art by large margins (see NVIDIA Titan V speedups above, and more hardware results next and in paper).
Key Approach
The proposed hardware-aware latency pruning (HALP) paradigm. Considering both performance and latency contributions, HALP formulates global structural pruning as a global resource allocation problem (Section 3.1), solvable using our augmented Knapsack algorithm (Section 3.2). Pruned architectures surpass prior work across varying latency constraints given changing network architectures for both classification and detection tasks (Section 4).
Our HALP paradigm on latency-saliency Knapsack.
More Results
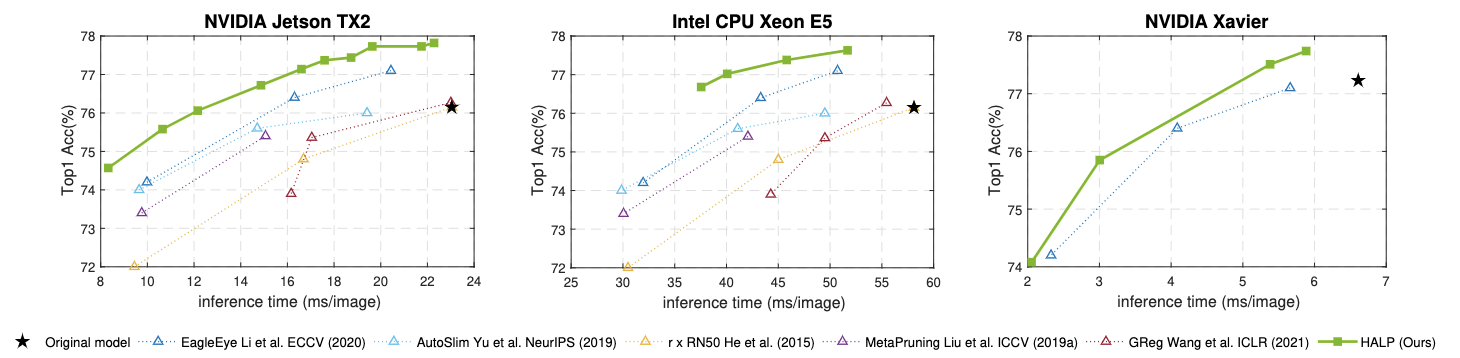
Our approach is fast and scalable across a wide range of target platforms for measured latency improvements. As an example, we show pruning results of ResNet50 on the ImageNet dataset with NVIDIA Jetson TX2 (left), Intel CPU Xeon E5 (middle) and NVIDIA Xavier (right). The latency on Jetson TX2 and CPU is measured using PyTorch; on Xavier is measured using TensorRT FP32.
Please refer to the paper for more details.
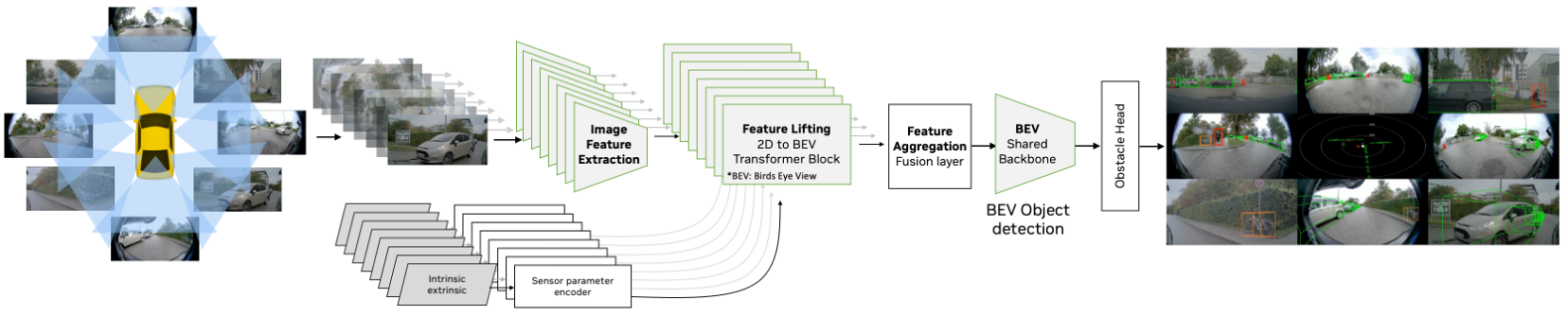
Application on 3D object detection and algorithm improvement
We further show the efficacy of the method on 3D object detection task and improve the algorithm in the following works:
Hardware-Aware Latency Pruning for Read-Time 3D Object Detection (IEEE IV 2023).
Soft Masking for Cost-Constrained Channel Pruning (ECCV 2022), where we improve the pruning performance especially for the large prune ratios.
Adaptive Sharpness-Aware Pruning for Robust Sparse Networks, where we aim at improving the robustness of compact models.
Hardware-Aware Latency Pruning for Read-Time 3D Object Detection
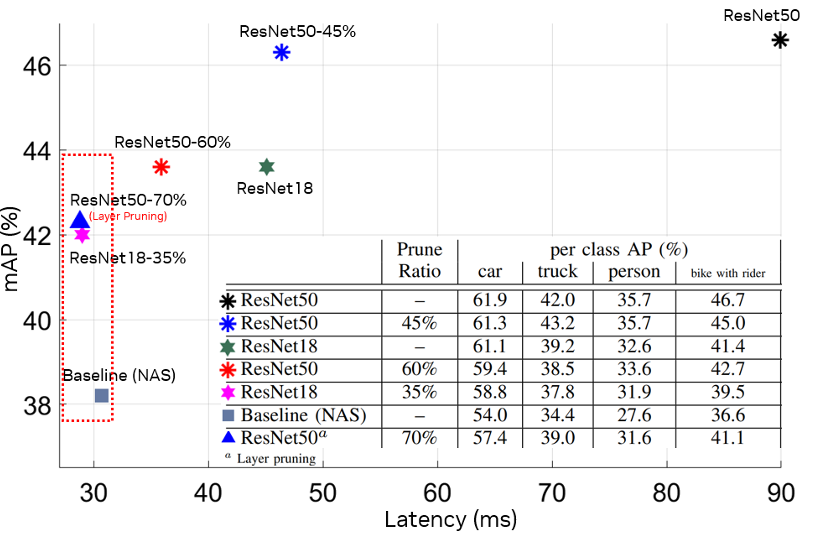
We present experiments on pruning for multi-camera 3D object detection and show the effectiveness of train large, then compress in the context of 3D object detection. For comparison, we use three different architectures (compact architecture search by NAS, ResNet18 and ResNet50) for the backbones and the encoder. We observe that:
1. Light pruning these architectures all yield a significant speedup with a similar accuracy compared to their dense counterpart;
2. Pruning a larger model to match the latency of a smaller one leads to better performance;
3. The performance of pruning a much larger model might be constrained by the model depth. Channel pruning should be considered to benefit the latency.
Paper
Structural Pruning via Latency-Saliency Knapsack, NeurIPS 2022.
@inproceedings{shen2022structural,
title={Structural Pruning via Latency-Saliency Knapsack},
author={Shen, Maying and Yin, Hongxu and Molchanov, Pavlo and Mao, Lei and Liu, Jianna and Alvarez, Jose},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{Humble2022pruning,
title={Soft Masking for Cost-Constrained Channel Pruning},
author={Humble, Ryan and Shen, Maying and Albericio-Latorre, Jorge and Darve, Eric and Alvarez, Jose M},
journal={ECCV},
year={2022}
}
@inproceedings{shen2023halp3d,
title={Hardware-Aware Latency Pruning for Real-Time 3D Object Detection},
author={Shen, Maying and Mao, Lei and Chen, Joshua and Sun, Xinglong and Knieps, Oliver and Maxim, Carmen and Alvarez, Jose},
booktitle={2023 IEEE Intelligent Vehicles Symposium (IV)},
year={2023},
organization={IEEE}
}
@article{bair2023ada,
title={Adaptive Sharpness-Aware Pruning for Robust Sparse Networks},
author={Bair, Anna and Yin, Hongxu and Shen, Maying and Molchanov, Pavlo and Alvarez, Jose M},
journal={arXiv preprint arXiv:2306.14306},
year={2023}
}